SEM高级进阶:教你短时间看懂描述性统计
导语:我要提前声明一下,这篇文章包含了统计知识。没有趣,简练得像“60%的统计数据是在现场进行的”这样的叙述,但实际上是陌生、枯燥的统计方法。玩笑归玩笑,我要介绍一些相当高级的统计分析方法,使它可以每一天都来帮你理解营销数据,做更好得战略决策。我保证这不会有痛苦。
我能听见你难以置信地说:“但是,我已经在做,我一直在分析我的数据!”
这很可能是事实——网站流量分析工具(谷歌统计、百度统计、CNZZ)的大多数用户都是本能地使用被正式称为“描述性统计”的方法。
例如,通过“目测”一个图表,你很容易在日访问流量中找出一个突升或突降。您使用平均值来快速评估营销的效果; 并且你能通过各种各样的比较帮你理解发生了什么,是否重要,及下一步需要做的事情。
尽管对于常用统计方法的坚持是好的、可行的,但我坚信,对一个因素的较真儿可以帮助你把数据分析提升到一个新的水平。下面,我会贯穿几个概念在一些现实世界的例子里,将有希望可以说服你,这是你应该考虑的一种新方法。
方差和标准差
每个数据集合都有几个的”特征”,当理解这些特征后,可以告诉你很多关于发生了什么、你可以期望在将来要做什么。 数据点的离散度是数据集合的主要特征之一,例如,某个测量结果与测量趋势之间的分散和差别有多大?标准差(SD)的正式测量,来自于对它的伙伴方差(σ2)的测量。从名字上你就能猜得出,这些指标能代表数据能被预测偏离多少,数据之间的差别程度。但是通过利用这些正式属性的准确性质,你可以做各种有用的事情。
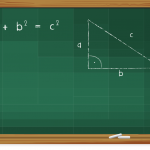
标准差是方差的平方根,为了计算方差,我们:
1、算出你的数据集的平均值。
2、用你的每一个数据减去第一步算出的平均值,然后把结果做平方。注意,每一个平方的结果都要记下来。
3、当第二步执行完后,把所有记下来的数据求和,取平均值,瞧,这就是你的方差。
为了得到标准差,需要把你计算的方差在开平方,这个计算看起来像下面这个公式:
在财务领域,标准差是衡量风险或波动性的关键度量-比如,在投资前,用这个指标衡量股票的投资组合的稳定性是非常有用的。整个投资组合可能会有高的平均产量并且提供很大的回报,但如果它的标准差比较高就说明这有可能是一场冒险的赌博,使你规避风险——不会把钱投进去。参考这个营销领域的例子,你正在为推广账户的一些计划分配月预算。你有两个计划,它们有可能花很多预算:
单纯地看ROI数据,可以简单的决定:把尽可能多的预算花在“Snow Shoes”上,把剩下的预算花在“Mammoth Fleece Coats”上。(我们这儿今天刚下过今年第一场雪,因此启发我起这样一个假的推广计划名字。)然而,如果我们分析数据,看看历史数据的偏差,我们会得到一些额外的东西,根据不同的目标,我们还可以有更多的战略思考:
现在,“Snow Shoes”计划仍然是一个有吸引力的选择;但是,需要考虑风险或波动性因素。一个混合投资策略(比”均衡投资组合”方法更复杂)将会确保你或你的客户的预算被更灵活的使用么?这完全取决于形势,但是这些额外的数据使你在一个更好的视角上发表观点,或做出决定。
查看这些数据的另一个行动是看看方差的大小。造成不同方差的根本原因是什么?你能有维持高收益并带来更低的标准差的行动么?
标准差和期望
在我前面的介绍里提到您能通过对分析数据集合的时间序列图表的目测,看出向上或向下的趋势。通过正式的方法,我们能计算出这些趋势的标准差,坚持原则的做出真实的正确决定。在公布的数据中,我们可以使用标准差作为某些测量”预期”的基准— — 例如,我们简单的假设每日的交易数据会被正常发布(这不大可能,但我做这种假设比较方便),68%的交易数据将落到距离平均值一个标准差之内,95%的交易数据将落在距离平均值两个标准差之内。
我们知道这个知识有什么用呢?作为营销人员,我们需要选择重点要解决的问题,以便充分利用手上有限的时间。我们用标准差做为期望值做为区分上升和下降的标准,要么”一切正常”,要么”嗯,有点意思,我应该投入时间研究一下”。让我们再来一遍,将这个新知识应用到下面的时间序列结果当中。首先,计算给定时间周期数据的标准差;第二,滚动累加计算平均值和标准偏差。
在我们的第一个图里,显示10月底下降进入了平均值的两个标准差里,所以我们应该看看为什么会这样。并且,我们还需要知道8月底发生了什么?
在第二个图里,从8月15日开始滚动累加计算平均值和标准差。我们看到其实从8月下旬开始到9月初,基本就处于平均值的第二个标准差了,说明这一时期波动性增加。同理,10月15日至25日,波动性也在增加,但在10月底,已经趋于平稳了。通过这个例子我们学到了什么?
统计的显著性:你的信心如何?
一个熟练掌握优化转化的人会利用统计的显著性做为一个简便的方法,统计的显著性可以告诉我们对数据观察出的结果是否是一些确定关联事物引起的,或者仅仅是数据里的随机事件。例如,当为优化一个网站的转化率而进行A/B测试和修改时,你需要确定任何测量数据的改进是归因于您的更改,并且这个可感知的结果不会蒙蔽了你的眼睛。统计的显著性、确定性也是一个可定义的测量数据。对某项工作产生的结果,你很少会有100%确定性。你可以设定一个目标值,比如,对网站非常棒的重新设计有95%的确定性能带来转化提升和快乐体验。
以下是影响统计的显著性结果的关键因素:
样本大小:你对某个事物测量的次数越多,你就越信任你的测量结果。如果你在一个会议室里有两个SEO人员和一个篮球运动员,用这三个人做样本来测量人的平均身高,你就会非常不自信。如果你随机测量了1000个人,你对平均身高的估计就会更加自信。(即使芝加哥公牛队也参加了你的SEO会议,这个估计也不会受到影响。)
标准差:我希望在前面得叙述中已经把标准差是什么说明白了。然而,只有标准差还不行,结合样本的数量,我们要计算平均值的标准误差(SE)。现在,先不要考虑如何计算,你要认识到你所期待的结果有一定程度的确定性(或不确定性,如果你是一个悲观的人),这种不确定性是依赖于你测量某事物的多少次,以及当你测量时的结果是如何变化的。
这是相关的例子,当分析下面这些数据时我们要考虑标准误差:
①付费搜索广告或程序化展示广告的效果。
②一个邮件营销推广的成功。
③不同类型内容的社会化营销参与率。
基于数据做决定的底线是你应当知道数据的确定性如何,你可以多大程度上依靠你正在看的数字。结论:我希望这些知识对于之前没有接触到这些概念的人是有用的,这些额外的步骤和方法都是与SEM的工作相关的。一项令人兴奋的、 持续的挑战是要使数据来讲故事,对于这个的目标来说这些知识只是冰山一角。
注:本文内容由九枝兰团队翻译,转载请加上本文链接以及微信ID:jiuzhilan。对于不署名者,九枝兰将保留追究的权利。
原作者:David Fothergill
译者:杨冬奕@九枝兰